TODO List
Abstract
A Compound Expression Recognition (CER) as a part of affective computing is a novel task in intelligent human-computer interaction and multimodal user interfaces. We propose a novel audio-visual method for CER. Our method relies on emotion recognition models that fuse modalities at the emotion probability level, while decisions regarding the prediction of compound expressions are based on the pair-wise sum of weighted emotion probability distributions. Notably, our method does not use any training data specific to the target task. Thus, the problem is a zero-shot classification task. The method is evaluated in multi-corpus training and cross-corpus validation setups. We achieved F1-score values equal to 32.15% and 25.56% for the AffWild2 and C-EXPR-DB test subsets without training on target corpus and target task, respectively. Therefore, our method is on par with methods developed training target corpus or target task.
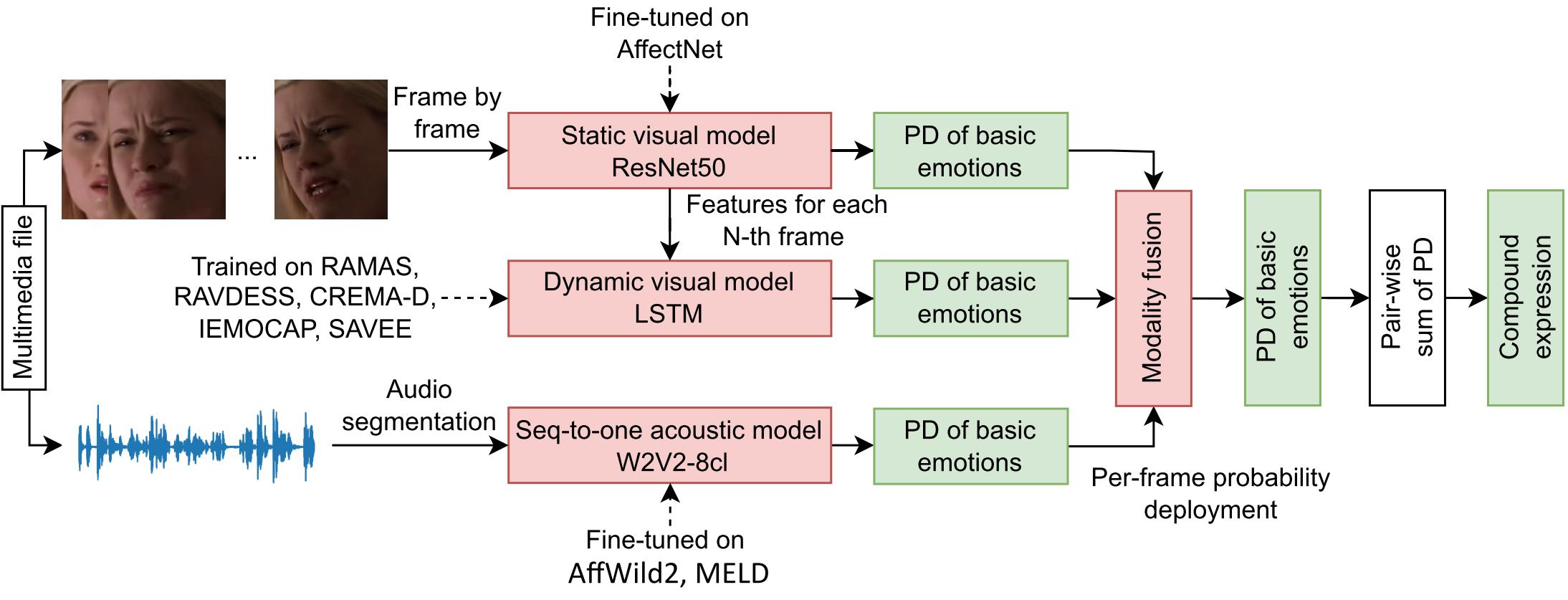
Pipeline of the proposed audio-visual CER method
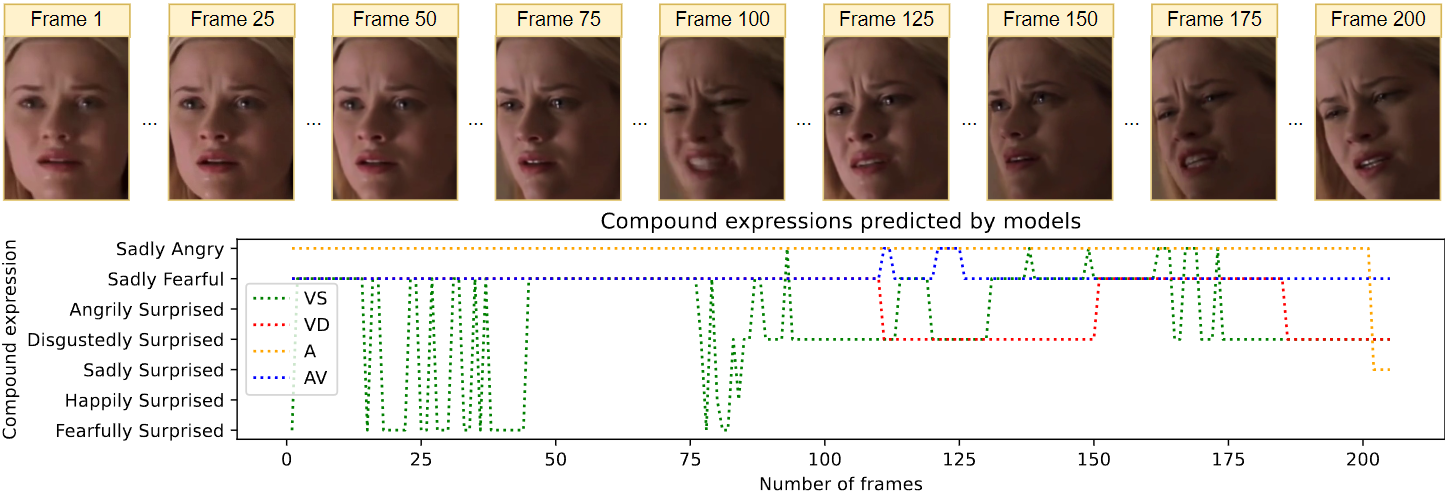
An example of CEs prediction using video from the C-EXPR-DB corpus
Conclusion
In this paper, we propose a novel audio-visual method for CER. The method integrates three models, including the static and dynamic visual models, as well as the audio model. Each model predicts the emotion probabilities for six basic emotions and the neutral state. The emotional probabilities are then weighted using the Dirichlet distribution. Finally, the pair-wise sum of weighted emotion probability distributions is applied to determine the compound emotions. Additionally, we provide new baselines for recognizing seven emotions on the validation subsets of the AffWild2 and AFEW corpora.
The experimental results demonstrate that each model is responsible for predicting specific Compound Expression (CE). For example, the acoustic model is responsible for predicting the Angry Surprised and Sadly Angry, the static visual model is responsible for predicting the Happily Surprised class, and the dynamic visual model predicts other CE well. In our future research, we aim to improve the generalization ability of the proposed method by adding a text model and increasing the number of heterogeneous training corpora for multi-corpus and cross-corpus studies.
Our Selected Research Papers
Journals
- Expert Systems with Applications 2024 OCEAN-AI Framework with EmoFormer Cross-Hemiface Attention Approach for Personality Traits Assessment, Elena Ryumina, Maxim Markitantov, Dmitry Ryumin, and Alexey Karpov
- Neurocomputing 2022 In Search of a Robust Facial Expressions Recognition Model: A Large-Scale Visual Cross-Corpus Study, Elena Ryumina, Denis Dresvyanskiy, and Alexey Karpov

Conferences
- ICASSP 2024 Audio-Visual Speech Recognition In-the-Wild: Multi-Angle Vehicle Cabin Corpus and Attention-based Method, Alexandr Axyonov, Dmitry Ryumin, Denis Ivanko, Alexey Kashevnik, Alexey Karpov
- INTERSPEECH 2023 Multimodal Personality Traits Assessment (MuPTA) Corpus: the Impact of Spontaneous and Read Speech, Elena Ryumina, Dmitry Ryumin, Maxim Markitantov, Heysem Kaya, and Alexey Karpov
- INTERSPEECH 2022 Biometric Russian Audio-Visual Extended MASKS (BRAVE-MASKS) Corpus: Multimodal Mask Type Recognition Task, Maxim Markitantov, Elena Ryumina, Dmitry Ryumin, and Alexey Karpov
- INTERSPEECH 2022 DAVIS: Driver's Audio-Visual Speech Recognition, Denis Ivanko, Dmitry Ryumin, Alexey Kashevnik, Alexandr Axyonov, Andrey Kitenko, Igor Lashkov, and Alexey Karpov
- INTERSPEECH 2021 Annotation Confidence vs. Training Sample Size: Trade-Off Solution for Partially-Continuous Categorical Emotion Recognition, Elena Ryumina, Oxana Verkholyak, and Alexey Karpov
- INTERSPEECH 2021 Annotation Confidence vs. Training Sample Size: Trade-Off Solution for Partially-Continuous Categorical Emotion Recognition, Oxana Verkholyak, Denis Dresvyanskiy, Anastasia Dvoynikova, Denis Kotov, Elena Ryumina, Alena Velichko, Danila Mamontov, Wolfgang Minker, and Alexey Karpov